


IV. Les outils de programmation▲
Cette partie dÃĐcrit deux outils fondamentaux pour le fonctionnement de GVLOGOÂ : les piles et l'ÃĐvaluateur d'expressions numÃĐriques.
IV-A. Les piles▲
IV-A-1. DÃĐfinition▲
Une pile informatique peut Être figurÃĐe par une pile d'assiettes posÃĐes sur une table : lorsque j'empile une donnÃĐe (push en anglais), je pose une assiette et lorsque je dÃĐpile une donnÃĐe (pull en anglais), je retire une assiette de la pile. La derniÃĻre donnÃĐe est donc la premiÃĻre à pouvoir Être extraite : on parle de pile LIFO (Last In First Out = dernier entrÃĐ, premier sorti). Une pile permet en fait de mÃĐmoriser les donnÃĐes manipulÃĐes dans l'ordre oÃđ elles seront à utiliser.
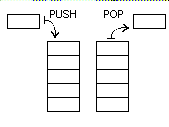
Les piles sont trÃĻs utilisÃĐes par GVLOGO. Elles permettent tout à la fois de faire fonctionner l'interprÃĐteur en stockant des donnÃĐes à rÃĐcupÃĐrer plus tard dans un certain ordre, et d'effectuer des calculs complexes, en particulier pour l'ÃĐvaluation d'expressions arithmÃĐtiques telles que (2 * 4,5) / 8. Comme la lecture d'une ligne de programme s'effectue par convention de la gauche vers la droite, si l'on rencontre une opÃĐration, rien n'indique a priori que les arguments nÃĐcessaires sont fournis : mentalement, nous dÃĐcouvrons les ÃĐlÃĐments au fur et à mesure de notre lecture. Un programme fait de mÊme !
IV-A-2. Exemples▲
Les exemples qui suivent seront trÃĻs dÃĐtaillÃĐs. En effet, le fonctionnement d'une pile est au cÅur de celui de l'interprÃĐteur lui-mÊme.
IV-A-2-a. Un exemple simple▲
On souhaite effectuer l'opÃĐration SOMME 24 35qui additionne les deux nombres fournis en paramÃĻtres. Pour cet exemple, on utilisera deux piles, la premiÃĻre contenant les donnÃĐes, la seconde les opÃĐrations à effectuer et le nombre de paramÃĻtres attendus.
Tout d'abord, on rencontre une opÃĐration à effectuer : ici, une addition. On sait qu'elle nÃĐcessite deux donnÃĐes : on empile cette opÃĐration et le nombre de paramÃĻtres attendus.
|
<pile vide> |
2 |
|
SOMME |
Ensuite, on rencontre une donnÃĐe. Afin de la mÃĐmoriser, on empile 24. SOMMEn'attend plus qu'un paramÃĻtre : on dÃĐcrÃĐmente le sommet de la seconde pile :
|
24 |
1 |
|
SOMME |
On rencontre encore une donnÃĐe. On empile 35et on dÃĐcrÃĐmente le sommet de l'autre pile :
|
35 |
0 |
|
24 |
SOMME |
Le 0 au sommet de la seconde pile indique que les donnÃĐes nÃĐcessaires sont acquises. On retire le sommet de la seconde pile pour en extraire l'opÃĐration qui peut à prÃĐsent Être effectuÃĐe.
|
35 |
SOMME |
|
24 |
On effectue alors l'addition sur la pile :
|
59 |
<pile vide> |
On rÃĐcupÃĻre le rÃĐsultat (59), par exemple pour l'afficher, et la premiÃĻre pile est vide.
Cette technique permet par consÃĐquent de mÃĐmoriser des rÃĐsultats intermÃĐdiaires : on peut imaginer que 35 est le rÃĐsultat d'une autre opÃĐration et sa prÃĐsence sur la pile fournira toujours le second ÃĐlÃĐment nÃĐcessaire à l'addition initiale.
IV-A-2-b. Un exemple plus complexe▲
On souhaite à prÃĐsent effectuer l'opÃĐration SOMME 24 PRODUIT 5 7, sachant que PRODUITmultiplie deux donnÃĐes sur la pile.
Tout d'abord, on rencontre l'opÃĐration à effectuer : ici, une addition. On sait qu'elle nÃĐcessite deux donnÃĐes :
|
<pile vide> |
2 |
|
SOMME |
Ensuite, on rencontre une donnÃĐe. Afin de la mÃĐmoriser, on empile 24.
SOMMEn'attend plus qu'un paramÃĻtre.
On dÃĐcrÃĐmente le sommet de la seconde pile :
|
24 |
1 |
|
SOMME |
On rencontre une seconde opÃĐration qui est PRODUIT, elle-mÊme nÃĐcessitant deux donnÃĐes. Il faut empiler ces informations :
|
24 |
2 |
|
PRODUIT |
|
|
1 |
|
|
SOMME |
La donnÃĐe suivante est 5, qu'on empile en dÃĐcrÃĐmentant par ailleurs le sommet de l'autre pile :
|
5 |
1 |
|
24 |
PRODUIT |
|
1 |
|
|
SOMME |
On a donc une opÃĐration SOMMEpendante qui attend encore une donnÃĐe et une opÃĐration PRODUITqui elle aussi attend une donnÃĐe.
La donnÃĐe suivante est 7 qu'on empile :
|
7 |
0 |
|
5 |
PRODUIT |
|
24 |
1 |
|
SOMME |
Le 0au sommet de la seconde pile indique que l'opÃĐration pendante qui la suit a les paramÃĻtres qu'elle attend à sa disposition. On dÃĐpile ce 0devenu inutile.
|
7 |
PRODUIT |
|
5 |
1 |
|
24 |
SOMME |
On rÃĐcupÃĻre alors PRODUIT. On peut donc effectuer cette opÃĐration et dÃĐposer son rÃĐsultat sur le sommet de la premiÃĻre pile en dÃĐcrÃĐmentant le sommet de la seconde pile.
|
35 |
0 |
|
24 |
SOMME |
On en a terminÃĐ avec la multiplication. La pile contient les deux donnÃĐes nÃĐcessaires à SOMME: on peut donc l'effectuer comme dans l'exemple 1.
Le 0 au sommet de la seconde pile indique que les donnÃĐes nÃĐcessaires sont acquises. On retire le sommet de la seconde pile pour en extraire l'opÃĐration qui peut à prÃĐsent Être effectuÃĐe.
|
35 |
SOMME |
|
24 |
On effectue alors l'addition sur la pile :
|
59 |
<pile vide> |
On rÃĐcupÃĻre le rÃĐsultat (59), par exemple pour l'afficher, et la premiÃĻre pile est vide.
Il est bien entendu que cet enchaÃŪnement d'opÃĐrations exige des ÃĐlÃĐments non encore rÃĐalisÃĐs :
- le flux du texte à exÃĐcuter doit Être acquis et analysÃĐ pour en dÃĐfinir les ÃĐlÃĐments de base ;
- il faut pouvoir distinguer une opÃĐration d'une donnÃĐe ;
- le nombre de paramÃĻtres d'une opÃĐration doit Être retrouvÃĐ pour Être empilÃĐ ;
- une pile fournit au minimum les moyens d'empiler et de dÃĐpiler une donnÃĐe. D'autres opÃĐrations ÃĐlÃĐmentaires sont souvent utiles : duplication de la derniÃĻre donnÃĐe, test de la profondeur de la pile, incrÃĐmentation et dÃĐcrÃĐmentation du sommetâĶ Les piles d'entiers et de rÃĐels fournissent d'autre part l'essentiel des opÃĐrations qu'on peut effectuer sur les donnÃĐes numÃĐriques qu'elles gÃĻrent : addition, soustractionâĶ
IV-A-3. OpÃĐrations sur les piles (et les queues)▲
GVLOGO n'a pas pour vocation de traiter des opÃĐrations de bas niveau comme les piles, mais il en fournit cependant une structure minimale. De plus, il implÃĐmente une structure de queue : les ÃĐlÃĐments sont alors stockÃĐs les uns aprÃĻs les autres, et c'est le plus ancien qui est dÃĐstockÃĐ le premier.
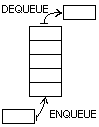
Les primitives ci-aprÃĻs sont dÃĐcrites dans ce chapitre, mais relÃĻvent du traitement des listes. Elles simulent le fonctionnement d'une pile ou d'une queue à partir d'une liste.
- EMPILE: attend le nom d'une variable puis un mot ou une liste - ne renvoie rien - la primitive place le second paramÃĻtre au dÃĐbut de la variable qui doit Être une liste.
Exemples :
EMPILE "MAPILE 124â -
EMPILE "MAPILE 568â -
-
SOMMET : attend le nom d'une variable en entrÃĐe - renvoie une liste ou un mot - la primitive renvoie le dernier ÃĐlÃĐment stockÃĐ dans la pile indiquÃĐe par le paramÃĻtre qui doit Être une liste, sans le retirer de cette derniÃĻre.
Exemple :
ECRIS SOMMET "MAPILEâ 568
-
DEPILE : attend le nom d'une variable en entrÃĐe - renvoie une liste ou un mot - la primitive renvoie le dernier ÃĐlÃĐment stockÃĐ dans la pile indiquÃĐe par le paramÃĻtre qui doit Être une liste, en le retirant de cette derniÃĻre.
Exemples :
ECRIS DEPILE "MAPILEâ 568
ECRIS DEPILE "MAPILEâ 124
-
QUEUEÂ : attend une variable puis une liste ou un mot en entrÃĐe - ne renvoie rien - la primitive stocke le second paramÃĻtre dans la premiÃĻre liste pour former une queue.
Exemple :
QUEUE "MAQUEUE [ceci est stockÃĐ]â -
- DEQUEUEÂ : attend une variable en entrÃĐe - renvoie une liste ou un mot - la primitive renvoie le premier ÃĐlÃĐment stockÃĐ dans une queue en le retirant de cette derniÃĻre.
Exemple :
ECRIS DEQUEUE "MAQUEUEâ un ancien ÃĐlÃĐment stockÃĐ
Les notions de queue et de pile sont trÃĻs souples pour GVLOGO si bien qu'il est possible de traiter n'importe quelle variable, pourvu qu'elle renvoie une liste. De plus, les primitives ENQUEUEet EMPILEsont strictement ÃĐquivalentes : on peut donc empiler une donnÃĐe et traiter la liste comme une pile, une queue ou une liste ordinaire, et rÃĐciproquement !
IV-A-4. ImplÃĐmentation des piles▲
L'unitÃĐ GVStacks offre une classe de pile gÃĐnÃĐrique et les classes nÃĐcessaires pour manipuler des entiers, des rÃĐels et des chaÃŪnes de caractÃĻres.
On aura tout intÃĐrÊt, si l'on utilise Delphi, à utiliser les piles fournies dans System.Generics.Collections(20). Comme Lazarus ne sait pas encore traiter les classes gÃĐnÃĐriques de maniÃĻre aussi satisfaisante que Delphi, la solution adoptÃĐe pour le projet est de travailler à partir d'une classe gÃĐnÃĐrique commune. Elle est plus limitÃĐe dans la mesure oÃđ elle ne connaÃŪt pas d'ÃĐnumÃĐration. D'autre part, la notification est moins complÃĻte, Lazarus n'acceptant que les classes comme support des gÃĐnÃĐriques. En revanche, plusieurs fonctionnalitÃĐs intÃĐressantes ont ÃĐtÃĐ ajoutÃĐes.
IV-A-4-a. Constantes▲
L'unitÃĐ GVConsts a ÃĐtÃĐ complÃĐtÃĐe. On a fixÃĐ la taille minimale de la pile à 8, ce qui permet de ne pas rÃĐallouer en permanence de la mÃĐmoire pour l'accroissement de la pile.
De nouvelles erreurs possibles ont ÃĐtÃĐ par ailleurs prÃĐvues dans GVErrConsts. On retrouve ces erreurs dans les chaÃŪnes de ressources :
IE_EmptyStack = 'ERREUR INTERNE - La pile interne "%s" est vide.';
IE_OutOfMemory =
'ERREUR INTERNE - La mÃĐmoire est insuffisante pour la pile "%s".';
IE_LowStack = 'ERREUR INTERNE - Pas assez d''ÃĐlÃĐments dans la pile "%s".';On remarquera que ces erreurs sont marquÃĐes comme internes, car elles ne se produiront que si notre programme final connaÃŪt un problÃĻme de conception.
Enfin, des constantes ÃĐnumÃĐrÃĐes ont ÃĐtÃĐ dÃĐfinies pour les notifications :
// *** notifications de la pile ***
// ajout, suppression, changement, effacement
TGVStackNotification = (stAdded, stRemoved, stChanged, stCleared);La premiÃĻre indique qu'un ÃĐlÃĐment a ÃĐtÃĐ ajoutÃĐ Ã la pile, la deuxiÃĻme qu'un ÃĐlÃĐment a ÃĐtÃĐ retirÃĐ, la troisiÃĻme qu'un changement autre est intervenu, la derniÃĻre que la pile a ÃĐtÃĐ remise à zÃĐro.
IV-A-4-b. La classe TGVSTack▲
Les piles sont implÃĐmentÃĐes en utilisant les classes gÃĐnÃĐriques. Pour rappel, ces classes fournissent un modÃĻle sur lequel viendront s'appuyer des classes spÃĐcialisÃĐes. Ainsi, à partir d'une seule classe de pile, on peut crÃĐer toutes les piles imaginables simplement en prÃĐcisant le type à utiliser.
Les avantages ÃĐvidents de cette mÃĐthode sur celle plus classique de dÃĐfinitions de classes au cas par cas sont un gain de temps, une souplesse largement accrue, une sÃĐcuritÃĐ renforcÃĐe puisque le code n'a pas à Être ressaisi pour chacune des classes et la possibilitÃĐ de modifier le comportement de toutes les classes spÃĐcialisÃĐes à partir de la seule modification de la classe gÃĐnÃĐrique :
// *** pile gÃĐnÃĐrique ***
generic TGVStack<T> = class(TObject)Les piles spÃĐcialisÃĐes prÃĐdÃĐfinies sont les suivantes :
// *** piles spÃĐcialisÃĐes ***
TGVIntegerStack = specialize TGVStack<Integer>;
TGVRealStack = specialize TGVStack<Real>;
TGVStringStack = specialize TGVStack<string>;
TGVDoubleStack = specialize TGVStack<Double>;
TGVExtendedStack = specialize TGVStack<Extended>;
TGVEvalStack = specialize TGVStack<TGVBaseItem>;En ce qui concerne l'interface de la classe TGVStack, en voici le listing :
// *** pile gÃĐnÃĐrique ***
generic TGVStack<T> = class(TObject)
private
fItems: array of T;
fError: TGVErrors; // gestionnaire des erreurs
fCount: Integer; // nombre d'ÃĐlÃĐments
fCapacity: Integer; // capacitÃĐ actuelle
fOnNotify: TGVStackEvent; // notification
procedure Expand; // expansion si nÃĐcessaire
function GetCapacity: Integer; // capacitÃĐ actuelle
function GetItem(N: Integer): T; // accÃĻs à un ÃĐlÃĐment
procedure SetCapacity(const Value: Integer); // fixe la capacitÃĐ
procedure SetItem(N: Integer; AValue: T);
protected
procedure Notify(Action: TGVStackNotification); virtual; // notification
procedure DoPush(const Value: T); // empilement
function DoPop: T; // dÃĐpilement
public
constructor Create; overload; // crÃĐation
destructor Destroy; override; // destruction
procedure Clear; // nettoyage
function IsEmpty: Boolean; inline; // pile vide ?
procedure Push(const Value: T); // empilement avec notification
function Pop: T; // dÃĐpilement avec notification
function Peek: T; // sommet de la pile
procedure Drop; // sommet de la pile ÃĐjectÃĐ
procedure Dup; // duplication au sommet de la pile
procedure Swap; // inversion au sommet de la pile
procedure Over; // duplication de l'avant-dernier
procedure Rot; // rotation au sommet de la pile
procedure Shrink; // contraction de la pile
function Needed(Nb: Integer): Boolean; // nombre d'ÃĐlÃĐments dÃĐsirÃĐs
property Count: Integer read fCount default 0; // compte des ÃĐlÃĐments
// capacitÃĐ de la pile
property Capacity: Integer read GetCapacity write SetCapacity
default CMinStack;
// accÃĻs direct à un ÃĐlÃĐment
property Item[N: Integer]: T read GetItem write SetItem; default;
// notification d'un changement
property OnNotify: TGVStackEvent read fOnNotify write fOnNotify;
// notification d'une erreur
property Error: TGVErrors read fError write fError;
end;Cette interface appelle les remarques suivantes :
- le paramÃĻtre T qui apparaÃŪt souvent sera celui remplacÃĐ par le type rÃĐel mis en Åuvre par la classe spÃĐcialisÃĐe ;
- le fondement de la pile est le tableau ouvert fItemsqui verra son dernier ÃĐlÃĐment pointÃĐ par le champ privÃĐ fCount;
- la notion de capacitÃĐ (à travers le champ privÃĐ fCapacity) complique un peu la classe, mais permet d'accÃĐlÃĐrer les empilements en ne procÃĐdant pas sans cesse à des allocations de mÃĐmoire ;
- la propriÃĐtÃĐ Itemest dÃĐfinie par dÃĐfaut, ce qui signifie par consÃĐquent que l'utilisateur n'a pas besoin de la spÃĐcifier (les deux ÃĐcritures sont ÃĐquivalentes : MaPile.Item[2]et Mapile[2]) ;
- la plupart des mÃĐthodes dÃĐfinies sont destinÃĐes à manipuler la pile : Push, Peek, Pop, Drop, Dup, Swap, Overet Rot. Les programmeurs en Forth reconnaÃŪtront là des outils trÃĻs familiers ;
- la prÃĐsence des mÃĐthodes DoPushet DoPopse justifie par le fait que ces opÃĐrations de base sur la pile sont employÃĐes par les autres mÃĐthodes qui ne doivent dÃĐclencher l'ÃĐvÃĐnement OnNotifyqu'une seule fois : ce sont donc deux mÃĐthodes qui ne notifient rien, contrairement à Pushet à Pop.
IV-A-4-c. Test de l'unitÃĐ TGVStacks▲
Pour ne pas changer, le programme de test est dÃĐclinÃĐ en deux versions :
- Lazarus pour Windows 32Â ;
- Lazarus pour Linux.
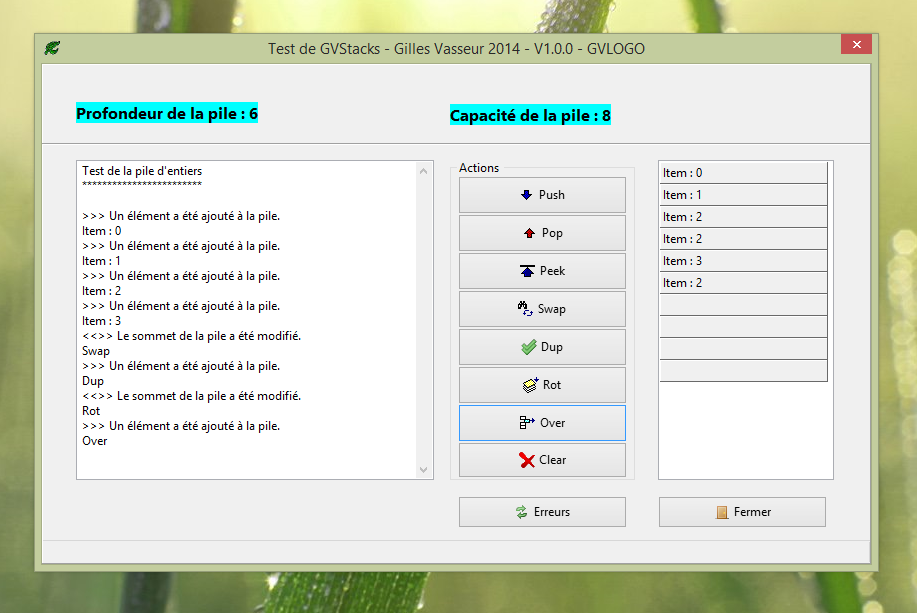
La mÃĐthode StackChangedexige quelques commentaires :
procedure TMainForm.StackChanged(Sender: TObject; Act: TGVStackNotification);
// changement de la pile
var
Li: Integer;
begin
for Li := 0 to fStackStr.Count - 1 do
sgStack.Cells[0,Li] := fStackStr[Li];
case Act of
stAdded : begin
mmoActions.Lines.Add('>>> Un ÃĐlÃĐment a ÃĐtÃĐ ajoutÃĐ Ã la pile.');
sgStack.RowCount := fStackStr.Count + 4;
end;
stRemoved : begin
mmoActions.Lines.Add('<<< Un ÃĐlÃĐment a ÃĐtÃĐ retirÃĐ de la pile.');
sgStack.Cells[0,fStackStr.Count] := EmptyStr;
end;
stChanged : mmoActions.Lines.Add('<<>> Le sommet de la pile a ÃĐtÃĐ modifiÃĐ.');
stCleared: begin
mmoActions.Lines.Add('000 La pile est vide.');
for Li := 0 to sgStack.RowCount -1 do
sgStack.Cells[0,Li] := EmptyStr;
end;
end;
if not fErr then // si erreur inactive
UpdateButtons;
end;Cette mÃĐthode a ÃĐtÃĐ affectÃĐe à la propriÃĐtÃĐ OnNotifyde la pile. Elle remplit le composant TStringGridavec les ÃĐlÃĐments de la pile, rÃĐpartit son travail suivant l'action notifiÃĐe et met à jour les boutons qui seront actifs ou non selon la profondeur de la pile. On remarquera la mise à jour permanente de la TStringGridafin de ne pas laisser de chaÃŪnes visibles aprÃĻs un dÃĐpilement, et l'augmentation si nÃĐcessaire du nombre de lignes disponibles, sans quoi une exception serait dÃĐclenchÃĐe pour un index hors limites.
Une autre mÃĐthode peut poser problÃĻme : il s'agit de celle appliquÃĐe lorsque l'utilisateur presse un bouton (btnPushClick). Cette mÃĐthode est partagÃĐe par tous les boutons de la fenÊtre. Afin de dÃĐterminer quel bouton a ÃĐtÃĐ pressÃĐ, on se sert de la propriÃĐtÃĐ TabOrderqui renvoie l'ordre du composant si l'utilisateur utilise la touche de tabulation.
On utilise plutÃīt la propriÃĐtÃĐ particuliÃĻre Tagqui a le mÃĐrite de ne pas dÃĐpendre de l'ordre des composants, mais qui ne vÃĐrifie pas qu'elle est unique. Avec TabOrder, on devra revoir le fichier source si l'on modifie l'ordre des composants ou si l'on en ajoute/supprime un. Ici, le choix de TabOrderne se justifie que par le parti pris pÃĐdagogique de montrer que plusieurs solutions existent quand il s'agit de rÃĐsoudre un problÃĻme !
En voici la dÃĐfinition :
procedure TMainForm.btnPushClick(Sender: TObject);
// actions
var
LS: string;
begin
case (Sender as TBitBtn).TabOrder of
0 : begin
LS := 'Item : ' + IntToStr(fStackStr.Count);
fStackStr.Push(LS);
end;
1 : LS := 'Pop : ' + fStackStr.Pop;
2 : LS := 'Peek : ' + fStackStr.Peek;
3 : begin
LS := 'Swap';
fStackStr.Swap;
end;
4 : begin
LS := 'Dup';
fStackStr.Dup;
end;
5 : begin
LS := 'Rot';
fStackStr.Rot;
end;
6 : begin
LS := 'Over';
fStackStr.Over;
end;
7 : begin
fStackStr.Clear;
fStackStr.Shrink;
mmoActions.Clear; // on nettoie l'affichage
LS := '*** CLEAR ***';
end;
end;
lblCapacity.Caption := 'CapacitÃĐ de la pile : ' +
IntToStr(fStackStr.Capacity);
lblDepth.Caption := 'Profondeur de la pile : ' +
IntToStr(fStackStr.Count);
if fStackStr.Error.OK then // si pas d'erreur
MmoActions.Lines.Append(LS) // on affiche
else
fStackStr.Error.Clear; // erreur annulÃĐe
end;Une chaÃŪne LSest prÃĐparÃĐe avant d'Être ajoutÃĐe au composant TMemo. Comme la taille de la pile peut Être modifiÃĐe, les composants TLabelcorrespondants sont ajustÃĐs.
Il pouvait Être plus judicieux de placer cette derniÃĻre mise à jour dans la mÃĐthode StackChangedqui couvre automatiquement tous les changements de la pile. Le lecteur pourra s'amuser à rÃĐaliser ce petit changement. Toutefois, il faut prendre garde de ne pas alourdir dÃĐmesurÃĐment les gestionnaires d'ÃĐvÃĐnements qui sont susceptibles d'Être appelÃĐs de maniÃĻre trÃĻs frÃĐquente : on observerait alors un ralentissement gÃĐnÃĐral des performances du programme.
IV-B. L'ÃĐvaluation d'une expression mathÃĐmatique▲
IV-B-1. DÃĐfinition▲
Un ÃĐvaluateur d'expressions mathÃĐmatiques est un module chargÃĐ d'ÃĐvaluer toute expression qui lui sera soumise, dans la limite des fonctions qu'il connaÃŪt.
Le calcul et l'ÃĐvaluation d'expressions interviennent frÃĐquemment dans les langages de programmation. La notation ordinaire du langage LOGO est la notation dite polonaise : on nomme l'opÃĐration pour la faire suivre par ses paramÃĻtres. Ainsi la somme de 4 et de 5 s'ÃĐcrira : SOMME 4 5.
Tant que les calculs sont simples, cette notation ne pose pas de problÃĻme, mais elle devient vite difficile à comprendre pour qui utilise d'habitude, comme tout un chacun, la notation infixe : par exemple, SOMME 4 PRODUIT 4 5 donnera comme rÃĐsultat 4 + (4 x 5), c'est-à -dire 24.
GVLOGO accepte aussi bien la notation polonaise prÃĐfixÃĐe que la notation infixe utilisÃĐe habituellement. Simplement, en cas d'utilisation de cette derniÃĻre, l'expression devra Être placÃĐe entre parenthÃĻses.
L'ÃĐvaluateur que GVLOGO propose accepte :
- les expressions imbriquÃĐes comme (4 * (5,6 / (4 + 8,2)) + 7,1) sans limite particuliÃĻre d'imbrication ;
- les variables comme :a, :var1, telles que dÃĐfinies par le programme auquel l'ÃĐvaluation appartient ;
- toute une sÃĐrie de fonctions dont la liste est fournie ci-aprÃĻs ;
- l'interface avec le systÃĻme de centralisation d'erreurs tel que dÃĐfini dans l'unitÃĐ GVErrors ;
- un systÃĻme de notifications des ÃĐvÃĐnements concernant l'ÃĐtat de l'ÃĐvaluateur.
Les deux systÃĻmes (polonais et notation infixe) ne peuvent pas Être utilisÃĐs simultanÃĐment au sein d'une expression avec parenthÃĻses. On peut donc ÃĐcrire SOMME 4 (7 * 8), mais pas (4 + PRODUIT 7 8). Une procÃĐdure ne peut pas non plus faire partie de l'expression.
GVLOGO utilise la virgule pour les nombres dÃĐcimaux, conformÃĐment à l'usage des ÃĐcoles. En revanche, comme tous les langages de programmation, il emploie * pour dÃĐnoter la multiplication afin d'ÃĐviter l'ambiguÃŊtÃĐ du signe x qui peut Être pris pour la lettre.
IV-B-2. OpÃĐrations dans l'ÃĐvaluateur▲
Les fonctions que connaÃŪt GVLOGO dans une expression avec parenthÃĻses sont plutÃīt nombreuses. Elles sont dÃĐfinies dans l'unitÃĐ GVPrimConsts :
MF_DAbs = 'ABS'; // valeur absolue
MF_DAbs2 = 'ABSOLUE';
MF_DCos = 'COS'; // cosinus
MF_DCos2 = 'COSINUS';
MF_DSin = 'SIN'; // sinus
MF_DSin2 = 'SINUS';
MF_DTan = 'TAN'; // tangente
MF_DTan2 = 'TANGENTE'; // 190
MF_DSqrt = 'RACINE'; // racine carrÃĐe
MF_DSqrt2 = 'RAC';
MF_DTrunc = 'TRONQUE'; // nombre tronquÃĐ
MF_DRound = 'ARRONDI'; // nombre arrondi
MF_DSqr = 'AU.CARRE'; // nombre au carrÃĐ
MF_DExp = 'EXP'; // exponentielle
MF_DFrac = 'FRAC'; // partie fractionnelle
MF_DInt = 'ENT'; // partie entiÃĻre
MF_DInt2 = 'ENTIER';
MF_DLn = 'LN'; // log nÃĐpÃĐrien // 200
MF_DLog2 = 'LOG2'; // log base 2
MF_DLog10 = 'LOG'; // log base 10
MF_DCoTan = 'COTAN'; // cotangente
MF_DCoTan2 = 'COTANGENTE';
MF_DArcCos = 'ARCCOS'; // arc cosinus
MF_DArcCos2 = 'ARCCOSINUS';
MF_DArcSin = 'ARCSIN'; // arc sinus
MF_DArcSin2 = 'ARCSINUS';
MF_DMinus = 'NEGATIF?'; // nombre nÃĐgatif ?
MF_DPLus = 'POSITIF?'; // nombre positif ? // 210
MF_DNegate = 'OPPOSE'; // signe inversÃĐ
MF_DSign = 'SIGNE'; // signe
MF_DRandom = 'HASARD'; // nombre au hasard
MF_Not = 'NON'; // nÃĐgation
// fonctions sans paramÃĻtres
MF_DPi = 'PI'; // PI sur la pile
MF_True = 'VRAI'; // valeur vrai
MF_False = 'FAUX'; // valeur faux
// fonctions infixes
MF_Or = 'OU'; // ou logique
MF_And = 'ET'; // et logique
MF_Mod = 'MOD'; // modulo // 220
MF_DPower = 'PUISSANCE'; // puissanceLes seules fonctions exclues sont celles qui font intervenir deux paramÃĻtres sans Être infixes : MINIMUM, MAXIMUMâĶ
IV-B-3. ImplÃĐmentation de l'ÃĐvaluateur▲
L'implÃĐmentation d'un systÃĻme d'ÃĐvaluation d'expressions est un problÃĻme classique dans le cadre d'une formation en informatique, mais classique ne signifie pas facile. Si des ÃĐvaluateurs sont disponibles sur Internet, ils sont souvent simplifiÃĐs : pas de variables, pas de fonctions, limitation des imbricationsâĶ Celui proposÃĐ ici tente de lever ces limitations.
IV-B-3-a. Les diffÃĐrentes notations▲
La notation infixe à laquelle nous sommes habituÃĐs n'est pas la plus simple à implÃĐmenter parce qu'elle doit faire usage de multiples parenthÃĻses pour lever les ambiguÃŊtÃĐs et/ou dÃĐfinir de maniÃĻre claire les prioritÃĐs des opÃĐrations. Par exemple, comment interprÃĐter sans rÃĻgles l'expression suivante : 4 + 5 * 6 ? Doit-on suivre l'ordre des opÃĐrateurs (ce qui donnera 4 + 5 = 9 ; 9 * 6 = 54) ? Dans la pratique, la plupart des langages de programmation fourniront un rÃĐsultat trÃĻs diffÃĐrent : 34 (obtenu en faisant 4 + 30 = 34). Ils auront en effet dÃĐfini une prioritÃĐ Ã la multiplication sur l'addition.
Dans le doute ou lorsqu'il veut rendre son travail parfaitement clair, un programmeur fera usage des parenthÃĻses qui sont toujours prioritaires sur les rÃĻgles deâĶ prioritÃĐÂ !
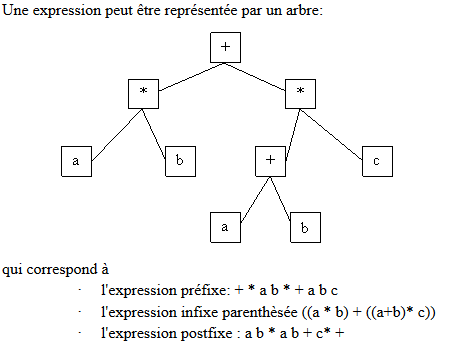
La notation induit alors une lecture particuliÃĻre de l'arbre, de la racine aux feuilles (notation prÃĐfixÃĐe ou polonaise, celle native de LOGO) ou au contraire en partant des feuilles pour aller vers la racine (notation postfixÃĐe ou polonaise inversÃĐe comme dans Forth et certaines calculatrices), ou encore un parcours qui monte et descend dans l'arbre (notation infixe utilisÃĐe en gÃĐnÃĐral).
DÃĐrivÃĐ de LISP, LOGO utilise la notation prÃĐfixÃĐe, car c'est la plus proche de l'expression naturelle des opÃĐrations à effectuer : faire la somme du produit de a et de b, et du produit de la somme de a et de b par c... Si cette ÂŦ clartÃĐ Âŧ ne vous paraÃŪt pas ÃĐvidente, essayez d'exprimer les mÊmes calculs avec les autres notationsâĶ
Le premier intÃĐrÊt des notations prÃĐfixÃĐe et postfixÃĐe est qu'elles peuvent se passer de parenthÃĻses si le nombre de paramÃĻtres de chaque fonction est connu et fixe. Le second intÃĐrÊt est qu'elles se prÊtent trÃĻs facilement à un traitement par piles, comme celles qui ont ÃĐtÃĐ dÃĐfinies dans le chapitre prÃĐcÃĐdent !
On trouve ainsi de nombreuses implÃĐmentations d'ÃĐvaluateurs qui font appel aux structures d'arbres et de piles. Parmi les plus pÃĐdagogiques, on consultera avec profit l'article de John Colibri (en français)(21).
IV-B-3-b. L'algorithme shunting-yard (gare de triage)▲
La documentation en français sur cet algorithme est rare alors qu'il est intÃĐressant à plus d'un ÃĐgard. Voici ce qu'en dit l'article de WikipÃĐdia en anglais :
In computer science, the shunting-yard algorithm is a method for parsing mathematical expressions specified in infix notation. It can be used to produce output in Reverse Polish notation (RPN)
[âĶ]
Like the evaluation of RPN, the shunting yard algorithm is stack-based(22)
Pour ceux qui ne lisent pas l'anglais, disons que cet algorithme convient tout à fait à notre objectif : fondÃĐ sur l'utilisation des piles, l'algorithme part d'une expression infixe pour aboutir à une expression postfixÃĐe inversÃĐe. Il est par ailleurs trÃĻs rapide, ne faisant appel qu'une seule fois à l'empilement de chaque donnÃĐe.
L'algorithme lui-mÊme est complexe : afin de ne pas alourdir le document prÃĐsent, le renvoi à l'article de WikipÃĐdia suffira. Il faut analyser le texte pour en extraire les unitÃĐs lexicales de base, les passer à la moulinette de notre algorithme qui utilisera une pile et rÃĐcupÃĐrer la valeur de retour. L'ensemble est lÃĐgÃĻrement compliquÃĐ par une gestion des erreurs.
L'algorithme exige tout d'abord de dÃĐcouper le texte d'entrÃĐe en unitÃĐs de base. On dÃĐfinit par consÃĐquent les diffÃĐrentes catÃĐgories possibles de ces unitÃĐs :
// *** ÃĐlÃĐments d'une expression à ÃĐvaluer ***
CTokensEnum = (cteInteger, cteReal, cteVar, cteFunction, cteBeginExp,
cteEndExp, ctePlus, cteMinus, cteMul, cteDiv, ctePower, cteGreater,
cteLower, cteEqual, cteNotEqual, cteGreaterOrEqual, cteLowerOrEqual, cteMod,
cteNot, cteAnd, cteOr, cteOrB, cteAndB, cteBoolean, cteUnKnown,
cteForbidden, cteNotSupported, cteUnaryMinus, cteUnaryPlus);
// *** ÃĐlÃĐment de base d'une expression ***
TGVBaseItem = record
Token: string; // ÃĐlÃĐment
Kind: CTokensEnum; // type d'ÃĐlÃĐment
end;Il exige par ailleurs de dÃĐfinir la prioritÃĐ de chaque ÃĐlÃĐment, ainsi que le type d'associativitÃĐ qu'il utilise :
// *** prioritÃĐ des ÃĐlÃĐments d'une expression ***
// nombre le plus ÃĐlevÃĐ = prioritÃĐ la moins ÃĐlevÃĐe
// -1 : ne s'applique pas
// 0: (unaires) - +
// 1: non
// 2: * / % mod
// 3: + -
// 4: > < <= >=
// 5: = <> !=
// 6: &
// 7: |
// 8: et
// 9: ou
// 10: ^ puissance
// 11: ( )
CTokenPrecedence: array [CTokensEnum] of Integer = (-1, -1, -1, -1, 11, 11, 3,
3, 2, 2, 10, 4, 4, 5, 5, 4, 4, 2, 1, 8, 9, 7, 6, -1, -1, -1, -1, 0, 0);
// *** associativitÃĐ des ÃĐlÃĐments ***
// 1 = droite - 0 = gauche - -1 = ne s'applique pas
CTokenAssociation: array [CTokensEnum] of Integer = (-1, -1, -1, -1, -1, -1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, -1, -1, -1, 0, 0);Pour le suivi de l'ÃĐtat de l'ÃĐvaluateur, on dÃĐfinit une ÃĐnumÃĐration des ÃĐtats possibles :
// *** ÃĐtats de l'ÃĐvaluateur ***
TGVEvalState = (esWaiting, esTokenizing, esScanning, esComputing,
esNoInit, esOK);IV-B-3-c. La classe TGVEval▲
L'interface de la classe TGVEvalcomprend de nombreuses mÃĐthodes en relation avec les fonctions utilisables dans une expression. On ne reproduit ici que les autres mÃĐthodes qui implÃĐmentent l'algorithme citÃĐ ou le mÃĐcanisme des ÃĐtats :
protected
// ajoute un ÃĐlÃĐment au tableau des ÃĐlÃĐments
procedure AddItem(const AItem: string; AKind: CTokensEnum); virtual;
// ajoute un ÃĐlÃĐment à la liste de scan
procedure AddScan(const AItem: TGVBaseItem); virtual;
procedure GetVar; virtual; // traitement des variables
procedure GetFunction; virtual; // traitement des fonctions
procedure GetNumber; virtual; // traitement des nombres
procedure Change; // notification de changement
procedure StateChange; // notification de changement de l'ÃĐtat
procedure Tokenize; // rÃĐpartition en ÃĐlÃĐments
procedure DoScan; // on analyse les ÃĐlÃĐments
procedure DoEvaluate; // on ÃĐvalue
public
constructor Create; overload; // constructeur simple
// constructeur avec initialisation
constructor Create(const AText: string); overload;
destructor Destroy; override; // destructeur
procedure Clear; // nettoyage
function GetEnumerator: TGVEvalEnumerator; // ÃĐnumÃĐration
procedure Scan; // ÃĐtudie la chaÃŪne entrÃĐe
function Association(AValue: CTokensEnum): Integer; // associativitÃĐ
function Precedence(AValue: CTokensEnum): Integer; // prioritÃĐ
property Text: string read fText write SetText; // expression à analyser
property ActualItem: string read fActualItem; // ÃĐlÃĐment en cours
property Res: Double read fResult; // rÃĐsultat de l'ÃĐvaluation
// index de dÃĐpart
property StartIndx: Integer read fStartIndx write SetStartIndx default 1;
property Indx: Integer read fIndx default -1; // index en cours dans la chaÃŪne
property Count: Integer read GetCount; // nombre d'ÃĐlÃĐments
property ScanCount: Integer read GetScanCount; // nombre d'ÃĐlÃĐments aprÃĻs scan
property Item[N: Integer]: TGVBaseItem read GetItem; default; // liste des ÃĐlÃĐments
property ScanItem[N: Integer]: TGVBaseItem read GetScanItem; // liste pour ÃĐvaluation
// ÃĐtat de l'ÃĐvaluateur
property State: TGVEvalState read fEvalState write SetState default esNoInit;
// notification d'une erreur
property Error: TGVErrors read fError write fError;
// ÃĐvÃĐnement liÃĐ Ã la recherche d'une variable globale
property Kernel: TGVLogoKernel read fKernel write fKernel;
// ÃĐvÃĐnement liÃĐ Ã la recherche d'une variable locale
property LocVars: TGVLocVars read fLocVar write fLocVar;
// ÃĐvÃĐnement liÃĐ Ã un changement
property OnChange: TNotifyEvent read fOnChange write fOnChange;
// ÃĐvÃĐnement liÃĐ Ã un changement
property OnStateChange: TNotifyEvent read fOnStateChange write fOnStateChange;
end;La mÃĐthode centrale est Scan, qui prend en charge les diffÃĐrentes ÃĐtapes conduisant du texte de dÃĐpart au rÃĐsultat :
procedure TGVEval.Scan;
// *** analyse de la chaÃŪne entrÃĐe ***
begin
if (State = esNoInit) then // erreur si rien à ÃĐvaluer
begin
// [### Erreur: non initialisation ###]
Error.SetError(CIE_NoInit, CE_GVLOGO);
Exit; // on sort
end;
try
Change; // notification de changement
Tokenize; // rÃĐpartition en ÃĐlÃĐments
if Error.OK then // pas d'erreur ?
DoScan; // on analyse
if Error.Ok then // toujours pas d'erreur ?
DoEvaluate; // on ÃĐvalue
finally
State := esWaiting; // ÃĐtat d'attente
end;
end;Ces ÃĐtapes sont par consÃĐquent :
- rÃĐpartition avec la mÃĐthode Tokenize;
- analyse avec la mÃĐthode DoScan;
- ÃĐvaluation avec la mÃĐthode DoEvaluate.
On interrompt le travail dÃĻs la premiÃĻre erreur rencontrÃĐe.
Tokenizes'occupe de balayer la chaÃŪne de caractÃĻres d'entrÃĐe pour isoler chaque unitÃĐ lexicale en l'associant à un type :
procedure TGVEval.Tokenize;
// *** rÃĐpartit en ÃĐlÃĐments ***
var
LCh: Char;
begin
State := esTokenizing; // ÃĐtat mis à jour
WipeItems; // liste interne nettoyÃĐe
fIndx := StartIndx; // dÃĐpart initialisÃĐ
// on balaie l'expression tant qu'il n'y a pas d'erreur
while Error.Ok and (fIndx <= Length(Text)) do
begin
LCh := fText[fIndx]; // caractÃĻre en cours
case LCh of
CBlank: Inc(fIndx); // on ignore les blancs
'0'..'9': GetNumber; // c'est un nombre
CColon: GetVar; // c'est une variable
CPlus: if (Count = 0) or (Item[Count].Kind = cteBeginExp) then
AddItem(CPlus, cteUnaryPlus) // plus unaire
else
AddItem(CPlus, ctePlus); // addition ou plus unaire
CMinus: if (Count = 0) or (Item[Count].Kind = cteBeginExp) then
AddItem(CMinus, cteUnaryMinus) // moins unaire
else
AddItem(CMinus, cteMinus); // soustraction ou moins unaire
CMul: AddItem(CMul, cteMul); // multiplication
CDiv: AddItem(CDiv, cteDiv); // division
CPower: AddItem(CPower, ctePower); // puissance
CGreater: GetDelimGreater; // plus grand ou >=
CLower: GetDelimLower; // plus petit ou <= ou <>
CEqual: AddItem(CEqual, cteEqual); // ÃĐgal
CNot: GetDelimNot; // nÃĐgation ou !=
COrB: AddItem(COrB, cteOrB); // ou logique |
CAndB: AddItem(CAndB, cteAndB); // et logique &
CBeginPar: AddItem(CBeginPar, cteBeginExp); // parenthÃĻse ouvrante
CEndPar: AddItem(CEndPar, cteEndExp); // parenthÃĻse fermante
'a'..'z', 'A'..'Z': GetFunction; // fonction
else
AddItem(LCh, cteUnknown); // enregistre le caractÃĻre interdit
// [### Erreur: caractÃĻre interdit ###]
Error.SetError(CE_BadChar, Text, fIndx - 1);
end;
end;
end;Les mÃĐthodes appelÃĐes sont celles auxquelles une tÃĒche particuliÃĻre est donnÃĐe : par exemple, GetFunctionest une des plus complexes.
Une fois ce travail rÃĐalisÃĐ, DoScans'occupe d'implÃĐmenter l'algorithme de shunting-yard. à la sortie, on doit avoir une liste des ordres rangÃĐs selon la notation polonaise inversÃĐe : en fait, un tableau d'enregistrements de type TGVBaseItem.
Pour cela, la mÃĐthode s'appuie sur le travail prÃĐcÃĐdent, en particulier la rÃĐpartition des unitÃĐs par types :
procedure TGVEval.DoScan;
// *** analyse des ÃĐlÃĐments (algorithme shunting-yard) ***
var
Li: Integer;
LBI1, LBI2: TGVBaseItem;
begin
State := esScanning; // ÃĐtat mis à jour
WipeScan; // nettoyage de la sortie
for Li := 1 to Count do // on balaie la liste
begin
LBI1 := Item[Li]; // ÃĐlÃĐment en cours
case LBI1.Kind of // on analyse sa nature
cteReal, cteInteger, cteVar, cteBoolean: // <==== une constante
AddScan(LBI1); // ÃĐlÃĐment pour la sortie
cteFunction: // <===== une fonction
fScanStack.Push(LBI1);
ctePlus, cteMinus, cteMul, cteDiv, ctePower, cteGreater, cteLower,
cteEqual, cteNotEqual, cteGreaterOrEqual, cteLowerOrEqual, cteMod,
cteNot, cteAnd, cteOr, cteOrB, cteAndB, cteUnaryMinus,
cteUnaryPlus: // <==== un opÃĐrateur
begin
while (not fScanStack.IsEmpty) // tant que la pile n'est pas vide
and (((Association(LBI1.Kind) = 0) and (Precedence(LBI1.Kind) >=
Precedence(fScanStack.Peek.Kind))) or
((Association(LBI1.Kind) = 1) and (Precedence(LBI1.Kind) <
Precedence(fScanStack.Peek.Kind)))) do
AddScan(fScanStack.Pop); // on stocke le sommet de la pile
fScanStack.Push(LBI1); // on empile le nouvel opÃĐrateur
end;
cteBeginExp: // <==== une parenthÃĻse ouvrante
fScanStack.Push(LBI1); // parenthÃĻse ouvrante empilÃĐe
cteEndExp: // <==== une parenthÃĻse fermante
begin
// tant que pile non vide et sommet <> (
while (not fScanStack.IsEmpty) and
(fScanStack.Peek.Kind <> cteBeginExp) do
AddScan(fScanStack.Pop); // on stocke le sommet de la pile
// parenthÃĻse ouvrante trouvÃĐe ?
if (not fScanStack.IsEmpty) and
(fScanStack.Peek.Kind = cteBeginExp) then
begin
fScanStack.Pop; // on retire la parenthÃĻse
if (not fScanStack.IsEmpty) and // pile non vide ?
// et fonction au sommet ?
(fScanStack.Peek.Kind = cteFunction) then
AddScan(fScanStack.Pop); // on stocke le sommet de la pile
end
else
begin
// [### Erreur: parenthÃĻses ###]
Error.SetError(CE_ParMismatch, Text, Li);
Break; // on quitte la boucle
end;
end;
end;
end;
if Error.OK then // pas d'erreur ?
begin
while (not fScanStack.IsEmpty) do
begin
LBI2 := fScanStack.Pop; // on rÃĐcupÃĻre le sommet
if (LBI2.Kind in [cteBeginExp, cteEndExp])then
begin
// [### Erreur: parenthÃĻses ###]
Error.SetError(CE_ParMismatch, Text);
Exit; // on quitte la procÃĐdure
end
else
AddScan(LBI2); // on stocke
end;
end;
end;La liste obtenue est alors directement exploitable pour l'ÃĐvaluation proprement dite. Cet ultime travail est effectuÃĐ par DoEvaluatequi inclut une sous-procÃĐdure DoFunction:
procedure TGVEval.DoEvaluate;
// *** ÃĐvaluation ***
var
Li: Integer;
LWhich: TGVBaseItem;
procedure DoFunction;
// traite une fonction
var
Lfunc: TGVFunctions;
begin
LFunc := WhichFunction(LWhich.Token); // numÃĐro de fonction
if fDStack.Needed(1) then // il faut un ÃĐlÃĐment sur la pile
begin
case LFunc of // choix de la fonction
C_DAbs, C_DAbs2: DoAbs; // valeur absolue
C_DCos, C_DCos2: DoCos; // cosinus
C_DSin, C_DSin2: DoSin; // sinus
C_DTan, C_DTan2: DoTan; // tangente
C_DSqrt, C_DSqrt2: DoSqrt; // racine carrÃĐe
C_DTrunc: DoTrunc; // nombre tronquÃĐ
C_DRound: DoRound; // nombre arrondi
C_DSqr: DoSqr; // nombre au carrÃĐ
C_DExp: DoExp; // exponentielle
C_DFrac: DoFrac; // partie fractionnelle
C_DInt, C_DInt2: DoInt; // partie entiÃĻre
C_DLn: DoLn; // log nÃĐpÃĐrien
C_DLog2: DoLog2; // log base 2
C_DLog10: DoLog10; // log base 10
C_DCoTan, C_DCoTan2: DoCoTan; // cotangente
C_DArcCos, C_DArcCos2: DoArcCos; // arc cosinus
C_DArcSin, C_DArcSin2: DoArcSin; // arc sinus
C_Minus: DoMinus;// nÃĐgatif ?
C_Plus: DoPlus; // positif ?
C_DNegate: DoNegate; // signe inversÃĐ
C_DSign: DoSign; // signe
C_DRandom: DoRandom; // entier au hasard
end;
end
else
// [### Erreur: pas assez d'arguments ###]
Error.SetError(CE_NoArg, Text, Li);
end;L'objectif de cette sous-procÃĐdure est de traiter les fonctions rencontrÃĐes en les rÃĐpartissant grÃĒce à une structure caseâĶof.
DoEvaluaterÃĐpartit de mÊme tous les autres ÃĐlÃĐments en balayant tout simplement le tableau rÃĐalisÃĐ lors des ÃĐtapes passÃĐes :
begin
State := esComputing; // ÃĐtat mis à jour
fResult := 0; // rÃĐsultat à zÃĐro
for Li := 1 to ScanCount do // on balaie les valeurs
begin
if not Error.OK then
Break; // on sort en cas d'erreur
LWhich := ScanItem[Li]; // ÃĐlÃĐment en cours
fActualItem := LWhich.Token; // ÃĐlÃĐment en cours stockÃĐ
Change; // notification de changement
with fDStack do
case LWhich.Kind of // rÃĐpartition suivant la nature de l'ÃĐlÃĐment
cteReal, cteInteger, cteVar,
cteBoolean: DoNumber(LWhich.Token); // nombre empilÃĐ
ctePlus: DoAdd; // addition ?
cteMinus: DoSub; // soustraction
cteMul: DoMul; // multiplication
cteDiv: DoDiv; // divivsion
ctePower: DoPower; // puissance
cteGreater: DoGreater; // >
cteLower: DoLower; // <
cteGreaterOrEqual: DoGreaterOrEqual; // >=
cteLowerOrEqual: DoLowerOrEqual; // <=
cteEqual: DoEqual; // =
cteNotEqual: DoNotEqual; // != ou <>
cteMod: DoMod; // mod
cteNot: DoNot; // non
cteOr, cteOrB: DoOr; // ou
cteAnd, cteAndB: DoAnd; // et
cteFunction: DoFunction; // une fonction
cteUnaryMinus: DoUnaryMinus; // moins unaire
cteUnaryPlus: DoUnaryPlus; // plus unaire
end;
end;
// rÃĐcupÃĐration du rÃĐsultat si disponible
if Error.OK then // pas d'erreur ?
begin
if fDStack.Count = 1 then // un ÃĐlÃĐment attendu pour le rÃĐsultat
begin
fResult := fDStack.Pop; // c'est celui qui est sur la pile
State := esOk; // rÃĐsultat trouvÃĐ
Change; // notification de changement
end
else
// [### Erreur: des ÃĐlÃĐments restent ###]
Error.SetError(CE_BadExp, Text);
end;
end;Le travail se fait par l'usage intensif de la pile fDStackde type TGVDoubleStack. Le rÃĐsultat final, s'il existe, est rÃĐcupÃĐrÃĐ au sommet de cette pile.
IV-B-3-d. Test de l'unitÃĐ GVEval▲
Contrairement aux autres unitÃĐs, l'unitÃĐ GVEval est fournie avec un programme de test qui ne pourra Être compilÃĐ qu'aprÃĻs le chapitre suivant. En effet, cette unitÃĐ est logiquement placÃĐe dans la partie ÂŦ outils de programmation Âŧ, mais elle fait appel pour l'utilisation des variables au noyau qui sera vu un peu plus tard.
Sans surprise, le programme de test est dÃĐclinÃĐ en deux versions :
- Lazarus pour Windows 32Â ;
- Lazarus pour Linux.
L'intÃĐrÊt qu'il prÃĐsente est de rendre explicite chacune des ÃĐtapes dÃĐcrites ci-dessus : il affiche aussi bien la dÃĐcomposition en unitÃĐs lexicales que la transformation en notation polonaise inversÃĐe. ParallÃĻlement sont affichÃĐs les diffÃĐrents ÃĐtats de l'ÃĐvaluateur. Les erreurs provoquent l'interruption de l'ÃĐvaluation et l'affichage de messages adaptÃĐs.
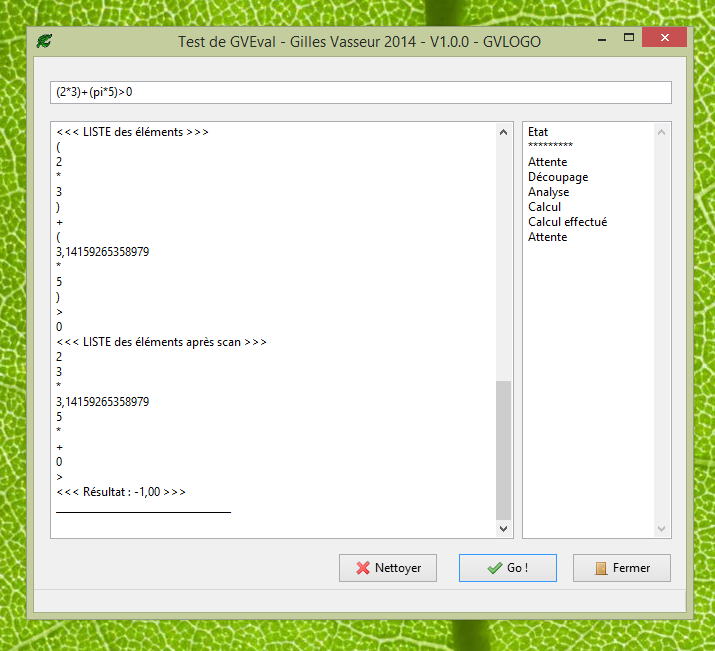
Sans surprise aussi, ce programme de test utilise les ÃĐlÃĐments dÃĐjà vus concernant la gestion des ÃĐvÃĐnements :
procedure TMainForm.FormCreate(Sender: TObject);
// crÃĐation de la fiche
begin
Kernel := TGVLogoKernel.Create; // noyau crÃĐÃĐ
// on crÃĐe des variables
Kernel.AddVar('var1', '123');
Kernel.AddVar('var2', '45,56');
Kernel.AddVar('var3', 'plouf');
Compute := TGVEval.Create; // objet crÃĐÃĐ
Compute.Kernel := Kernel;
Compute.Error.OnError := @GetError; // gestionnaire d'erreurs
Compute.OnChange := @GetChange; // gestionnaire de changement
Compute.OnStateChange := @GetStateChange; // gestionnaire de changement d'ÃĐtat
end;