




I. Introduction▲
Dans l'informatique moderne, le recours à des services, des fonctions ou des mécanismes cryptographiques est devenu très courant. Initialement majoritairement réservés à la protection de la confidentialité des données, les algorithmes cryptographiques sont aujourd'hui aussi utilisés pour vérifier leur intégrité, assurer leur origine ou encore apporter une preuve, de transaction par exemple.
Dans cet article, nous allons passer en revue différentes primitives cryptographiques, leur finalité et nous allons montrer à l'aide d'exemples avec le TMS Cryptography Pack comment les utiliser de manière sûre. Cinq familles sont proposées : les algorithmes de chiffrement symétrique, les algorithmes de chiffrement asymétrique, les fonctions de hachage, les fonctions de dérivation de clé et les générateurs de nombres aléatoires.
La dernière section traite le point crucial qu'est la gestion des différentes clés pour activer ces primitives.
II. Les algorithmes de chiffrement symétrique▲
Ces algorithmes doivent leur nom au fait que la même clé est utilisée pour chiffrer un texte, ou un message, et pour le déchiffrer. Ils utilisent une série de fonctions inversibles qui permettent de produire un chiffré, ou un cryptogramme, à partir d'un clair.

L'exemple le plus connu d'algorithme de chiffrement symétrique est le Data Encryption Standard (DES), sans doute suivi de l'Advanced Encryption Standard (AES). Le DES ne fonctionnant qu'avec des clés de 56 bits, il est à bannir pour protéger des données sensibles.
Il y a de nombreuses autres considérations que la taille de clé pour considérer qu'un algorithme est sûr, mais elles dépassent le cadre de cet article.
L'AES est à privilégier pour chiffrer des données alors que SPECK peut être utilisé avec des processeurs de faible puissance, comme les processeurs embarqués en général, à la réserve près qu'il a été conçu par la NSA et qu'il faut donc se garder de chiffrer des données très sensibles en l'état actuel des connaissances.
Les algorithmes de chiffrement symétrique sont classés en deux types : chiffrement de blocs (ex. AES, SPECK) ou de flux (ex. SALSA20). Ces derniers sont adaptés à la protection de la voix ou de la vidéo. Il est assez simple de transformer un algorithme de chiffrement de bloc en chiffrement de flux, mais les performances sont en général moins bonnes.
Il est aussi important d'utiliser des tailles de bloc suffisamment importantes pour contrer les attaques du type « paradoxe de l'anniversaire ». À ce titre, SPECK ne devrait être utilisé qu'avec des blocs de 128 bits.
Le paradoxe des anniversaires est une estimation probabiliste du nombre de personnes que l'on doit réunir pour avoir une chance sur deux que deux personnes de ce groupe aient leur anniversaire le même jour. Il se trouve que ce nombre est 23, ce qui choque un peu l'intuition. À partir d'un groupe de 57 personnes, la probabilité est supérieure à 99 %.
Appliqué à la cryptographie, et en fonction du mode de chiffrement utilisé et de ses propriétés, il implique que pour une taille de bloc de n bits, il faut 2 puissance n/2 blocs environ pour obtenir une collision, c'est-à-dire que deux messages distincts permettent d'obtenir le même cryptogramme avec une clé identique. On peut alors en déduire la clé. Il faut donc choisir une taille de bloc élevée et renouveler la clé très souvent.
Voici une portion de code avec TMS Cryptography Pack qui met en œuvre le chiffrement AES et nettoie la clé après usage :
aes := TAESEncryption.Create;
try
aes.AType := atcbc; // select CBC mode
aes.KeyLength := kl128; // clé de 128 bits
aes.OutputFormat := base64;
aes.key := '123456789012345'; // pourrait sortir d'Argon2 (voir V)
aes.IVMode := TIVMode.rand; // vecteur d'initialisation aléatoire
aes.paddingMode := TPaddingMode.PKCS7;
aes.Unicode := yesUni;
s:= aes.Encrypt('test');
finally
aes.Free; // cette opération effectue aussi la remise à zéro des variables cryptographiques
end;Dans cet exemple, il est important de noter que les variables cryptographiques doivent être « nettoyées » après usage. Cette mesure est essentielle, mais pas nécessairement suffisante, car il n'est pas possible de contrôler l'exécution du programme et l'accès à ses données par le système d'exploitation.
En pratique, il est important que les clés soient réellement aléatoires et changées régulièrement.
III. Les algorithmes de chiffrement asymétrique▲
Sans grande surprise, les algorithmes de chiffrement asymétrique doivent leur nom au fait que les clés de chiffrement et de déchiffrement sont différentes. En pratique, ces algorithmes, dont RSA est le plus célèbre, sont très lents par rapport à leurs cousins de chiffrement symétrique et ne sont pas utilisés pour chiffrer de gros volumes. Ils sont le plus souvent utilisés pour signer et vérifier une signature et pour chiffrer des clés, dans le cadre d'un échange par exemple, quand leur fonctionnement le permet.
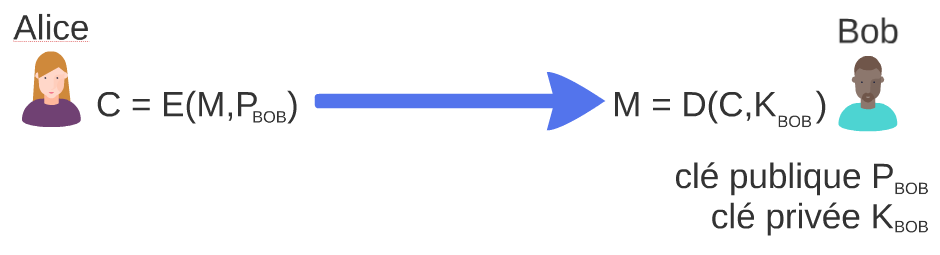
Voici une signature avec la courbe elliptique 25519 :
ecc := TECCEncSign.Create;
try
ecc.ECCType := cc25519; // on choisit la courbe Ed25519
ecc.OutputFormat := hexa;
ecc.PublicKey := BobPublicKey; // en hexa
ecc.Unicode := yesUni;
ecc.NaCl := naclNo; // pas de compatibilité avec libsodium sous Linux
s := ecc.Encrypt('test');
finally
ecc.Free; // cette opération effectue aussi la remise à zéro des variables cryptographiques
end;Pour les clés publiques (on devrait dire publiées) et privées, on parle soit de bi-clés soit de paire de clés.
Les courbes elliptiques sont un cas particulier de courbe algébrique. En cryptologie, elles sont utilisées pour des échanges de clés ou pour le chiffrement asymétrique. Elles donnent des clés plus courtes que celles fournies par des systèmes de type RSA, avec un niveau de sécurité au moins équivalent.
IV. Les fonctions de hachage▲
Une fonction cryptographique de hachage permet de générer un condensat (ou hash) pour un fichier ou un bloc de données avec une probabilité quasi-nulle d'obtenir le même condensat avec deux fichiers ou deux blocs différents.
Les fonctions de hachage ont d'autres propriétés mais qui dépassent le cadre de cet article.
Les fonctions de hachage les plus connues sont sans doute SHA1 et MD5, mais elles sont toutes les deux à bannir car considérées trop faibles sur un plan cryptographique, surtout pour MD5. Il faut leur préférer SHA2 et SHA3, qui sont à la fois plus sûres et, pour la dernière, bien plus moderne et souple.
Le condensat, stocké ou transmis par un autre moyen, permet de vérifier l'intégrité des données. Il suffit pour cela de le recalculer et de comparer le résultat avec l'original.
Les fonctions de signature utilisent un condensat pour leurs opérations. En pratique, le condensat d'un fichier ou d'un bloc de données est calculé puis signé ou vérifié.
Voici un exemple d'utilisation de SHA3 :
sha3 := TSHA3Hash.Create;
try
sha2.HashSizeBits := 256;
sha3.OutputFormat := base64url;
sha3.Unicode := yesUni;
s := sha3.Hash('test');
finally
sha3.Free;
end;Une variante du condensat est le condensat avec secret obtenu par une fonction appelée keyed-Hash Message Authentication Code ou HMAC. Dans cette fonction, le condensat est calculé à partir d'un message ou d'un bloc complété d'une clé secrète. Il n'est possible de recalculer le HMAC que si l'on connaît cette clé.
V. Les fonctions de dérivation de clé▲
Les clés utilisées pour les algorithmes de chiffrement symétrique doivent être aléatoires, ou ne pas être générées à partir d'une séquence facile à deviner. En pratique, il est très compliqué de demander à un utilisateur de fournir directement une clé de 16 ou 32 octets (128 ou 256 bits) et il est préférable d'avoir recours à une fonction de dérivation de clé à partir d'un mot de passe.
Les deux fonctions les plus connues pour dériver des clés sont PBKDF2 et Argon2, la seconde étant un standard en devenir.
Ces fonctions acceptent un mot de passe et une variable appelée « sel » en entrée. Le « sel », dont le nom français devrait plutôt être « piment », est une valeur qui sert à augmenter l'entropie. En pratique, le « sel » tend à rendre une recherche exhaustive du mot de passe plus complexe si ce « sel » est long. Cette recherche devient impossible à faire en partant de condensats précalculés pour chaque valeur du « sel », car ils sont alors bien trop nombreux à générer et à stocker.
Une fonction de dérivation de clé sert aussi à protéger un mot de passe : il suffit en effet de stocker la clé qui résulte du calcul ainsi que le « sel » puis de comparer, par exemple à chaque tentative de connexion, la valeur calculée à partir du mot de passe entré par l'utilisateur avec la valeur stockée (en utilisant le même « sel » dans les deux cas) pour valider ou non l'accès.
Voici un exemple d'utilisation d'ARGON2 :
argon2 := Targon2KeyDerivation.Create;
try
argon2.OutputFormat := base32;
argon2.OutputSizeBytes := 16;
argon2.Counter := 10;
argon2.Memory := 16;
argon2.StringSalt := '0123456789012345';
argon2.Unicode := yesUni;
k := argon2.GenerateKey('password123:');
// on peut demander un MDP à l'utilisateur via une boîte de dialogue
finally
argon2.Free;
end;VI. Les générateurs de nombres aléatoires▲
La cryptographie ne serait pas grand-chose sans les nombres aléatoires et leurs générateurs (RNG). Comme il est très difficile de produire des nombres de manière réellement aléatoire en logiciel (nous ne traitons pas le cas du matériel pour lequel il existe des techniques éprouvées ), de nombreuses fonctions ont été développées au fil du temps et certains générateurs sont considérés comme sûrs sur un plan cryptographique. C'est le cas de Fortuna, repris par la CryptoAPI de Microsoft avec une fonction comme CryptGenRandom.
Les systèmes de souche Unix ou Linux fournissent les périphériques /dev/random et /dev/urandom qu'il suffit de lire pour obtenir un nombre. La différence entre ces deux périphériques est leur temps de réponse et il n'y a pas d'élément montrant que l'un est plus sûr que l'autre sur un plan cryptographique. Ces générateurs sont nommés générateurs pseudo-aléatoires (PRNG).
/dev/random est bloquant, c'est-à-dire qu'il cesse de fournir des octets si le système considère que ce n'est pas sûr.
Voici un exemple en C d'utilisation de CryptGenRandom sous Windows :
// RandomUBuffer: return a random Buffer
// Input : unsigned int len (the length of the Buffer)
// unsigned char* MyBuffer (the output Buffer)
// Output : code of error
// Windows only
int RandomUBuffer(unsigned int len, unsigned char* MyBuffer) {
int err;
HCRYPTPROV hProvider = 0;
if (!CryptAcquireContext(&hProvider, 0, 0, PROV_RSA_FULL,
CRYPT_VERIFYCONTEXT | CRYPT_SILENT)) {
err = ER_ERROR_RANDOM_INT_1;
return err;
}
if (!CryptGenRandom(hProvider, (DWORD)len, (BYTE*)MyBuffer)) {
CryptReleaseContext(hProvider, 0);
err = ER_ERROR_RANDOM_INT_1;
return err;
}
if (!CryptReleaseContext(hProvider, 0)) {
err = ER_ERROR_RANDOM_INT_1;
return err;
}
return ER_SUCCESS;
}Sous Linux, voici une portion de code utilisant /dev/urandom :
// Output : code of error
// OSX, Unix, Linux
int RandomUBuffer(unsigned int len, unsigned char* MyBuffer) {
bool test = false;
int compt = 0;
int fHandle = open("/dev/urandom", O_RDONLY);
int result;
if (fHandle == -1) {
// error, unable to read /dev/urandom
return ER_ERROR_RANDOM_INT_1;
}
result = read(fHandle, MyBuffer, len);
if (result == len) {
test = true;
}
compt += result;
while (test == false) {
result = read(fHandle, MyBuffer + compt, len - compt);
compt += result;
if (compt >= len) {
test = true;
}
}
close(fHandle);
return ER_SUCCESS;
}Les générateurs de nombres aléatoires sont utilisés pour produire des clés symétriques ainsi que dans le processus de génération des clés asymétriques (pour générer un nombre premier par exemple).
VII. La gestion des clés▲
Dans la mesure où les algorithmes utilisés sont sûrs et où leur codage est correct, un adversaire n'a que peu d'options pour conduire une attaque ayant une chance de se conclure par un succès. Il doit chercher à s'emparer des clés ou à les deviner.
Pour l'empêcher de les deviner, on utilisera un générateur de nombre aléatoire et pour assurer une gestion correcte des clés (et des certificats associés), on utilisera éventuellement une Infrastructure de Gestion de Clé, pour les clés publiques, et des algorithmes d'échange de clé, pour les clés symétriques.
VIII. Recommandations sur la taille des clés et des condensats▲
Quand la puissance de calcul le permet, il est recommandé d'utiliser la taille maximale de clé possible pour un algorithme donné, par exemple, 256 bits pour l'AES.
Le cas du RSA est plus problématique, car la taille de la clé a un impact très significatif sur les performances, mais une taille minimale de 2048 bits est recommandée.
Le site www.keylength.com fournit un comparatif des recommandations sur les tailles de clés pour protéger des données en fonction d'une échéance.
Voici un comparatif des tailles de clé :

On note que TMS CP autorise les cas présentés dans la figure suivante et supporte le maximum proposé dans les recommandations de la table des tailles de clé ci-dessus et souvent bien au-delà, sauf pour SPECK qui par construction n'accepte au mieux que des clés de 128 bits (mais il est fait pour des objets connectés de faible puissance).
Voici les tailles de clés supportées par le TMS Cryptography Pack :

IX. Conclusion▲
Le développement d'algorithmes cryptographiques reste compliqué et nécessite de très solides compétences en mathématiques ainsi qu'une longue expérience des techniques d'attaques sur les différents types d'algorithmes. Le recours à des standards éprouvés comme ceux cités dans cet article est plus que recommandé et il faut absolument éviter de se reposer sur des algorithmes « maison », sauf cas très particuliers.
De même, le codage et l'utilisation concrète des algorithmes ne sont pas exempts de pièges et d'erreurs en tous genres. Il est nécessaire de respecter quelques règles de base pour coder des algorithmes et au minimum, il faut :
- passer les cas de test du standard concerné quand ils existent (FIPS, RFC, implantation de référence) ;
- compléter ces tests par des tests sur des cas particuliers (chaîne vide, fichier vide, chaîne contenant un zéro, très gros fichier, etc.) ;
- « nettoyer » des variables internes dès que possible et avant libération ;
- tester les bornes minimales et maximales sur les entrées.
Pour ce qui concerne l'emploi des fonctions mettant en œuvre ces algorithmes dans du logiciel, il faut penser à :
- utiliser un algorithme à bon escient et avec le bon mode ;
- initialiser correctement ce qui doit l'être ;
- « nettoyer » les variables contenant les éléments secrets après utilisation ;
- changer régulièrement les clés de chiffrement ;
- révoquer les certificats compromis (perdus, volés ou éventuellement « cassés ») ;
- contraindre les entrées faites par l'utilisateur ;
- valider les sorties (vérifier ce qui peut l'être) ;
- prévoir et traiter les cas où la fonction « plante ».
Je remercie Marion Candau pour les dessins, les exemples et ses suggestions, Sarah Bordage pour ses commentaires, alcatîz pour la relecture technique et XXXXXX pour la relecture orthographique.
Pour en savoir plus : Introduction à la cryptographie